Sentiment Analysis in PythonIn this article, we will discuss sentiment analysis in Python. This application proves again that how versatile this programming language is. But before starting sentiment analysis, let us see what is the background that all of us must be aware of- So, here we'll discuss-
Let us start with Natural Language Processing- To put it in simple words we can say that computers can understand and process the human language. The objective here is to obtain useful information from the textual data. The raw data which is given as an input undergoes various stages of processing so that we perform the required operations on it. In the stage of data cleaning, we obtain a list of words which is called clean text. Some of the steps involved in this are tokenization, stop word removal, stemming, and vectorization (processing of converting words into numbers), and then finally we perform classification which is also known as text tagging or text categorization, here we classify our text into well-defined groups. So, this was all about Natural Language Processing, now let us see how the open-source tool Natural Language Processing Toolkit can help us. This is a platform that we use to write Python programs that can be applied for implementing all the pre-processing stages of natural language processing. Now, the next task is to classify our text which can be done using the Na�ve Bayes Algorithm, so let us understand how does it work? The principle of this supervised algorithm is based on Bayes Theorem and we use this theorem to find the conditional probability. The Bayes theorem is represented by the given mathematical formula- P(A|B) = P(B|A)*P(A)/P(B) P(A|B)(Posterior Probability) - Probability of occurrence of event A when event B has already occurred. P(B|A)(Likelihood Probability) - Probability of occurrence of event B when event A has already occurred P(A)(Prior)- Probability of occurrence of event A. P(B)(Marginal)-Probability of occurrence of event B. Sentiment AnalysisAfter knowing the pre-requisites let's try to understand in detail that what sentiment analysis is all about and how we can implement this in Python? Sentiment analysis is used to detect or recognize the sentiment which is contained in the text. This analysis helps us to get the reference of our text which means we can understand that the content is positive, negative, or neutral. Looking at the current scenario, all the business tycoons need to have a lucid idea of what kind of response their product is receiving from the customers and how the changes can be incorporated based on the arising demands. Following are the steps involved in the process of sentiment analysis-
Let us understand this with the help of an example- Here we have taken some sentences in our training dataset(x_train) and values 0 and 1 in y_train where 1 denotes positive and 0 denotes negative. Code Output 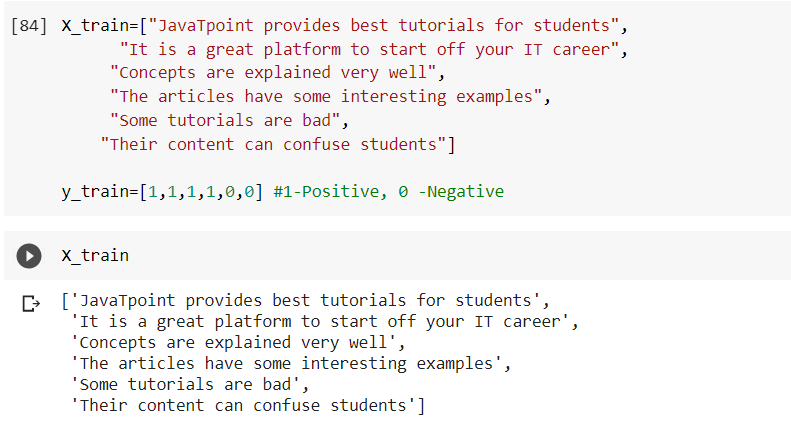 2. The next step is to import the required libraries that will help us to implement the major processes involved in natural language processing. Let us understand what the processes Tokenization, Stemming & Stopwords-
Code Output  3. The next step is to create objects of tokenizer, stopwords, and PortStemmer. We want to concatenate the words so we will use regex and pass \w+ as a parameter. Since we are using the English language, we will specify 'english' as our parameter in stopwords. Code Output  4. The next step is to create a function that will clean our data. We will convert our text into lower case and then implement tokenization. In the given function, we are performing tokenization and stopword removal at the same time. (token for token in tokens if token not in en_stopwords) The next thing is to perform stemming and then join the stemmed tokens. Code Output  5. Following is our x_test data which will be used for cleaning purposes. Code Output  6. In this step, we have taken our data from X_train and X_test and cleaned it. Code Output  7. When we want to check how our clean data looks, we can do it by typing X_clean- Code Output 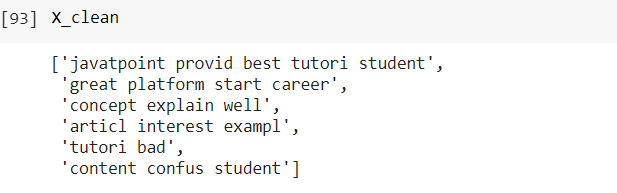 8. Before going for classification, it is important to perform vectorization to get the desired format. For that, we have to import some libraries. Code Output 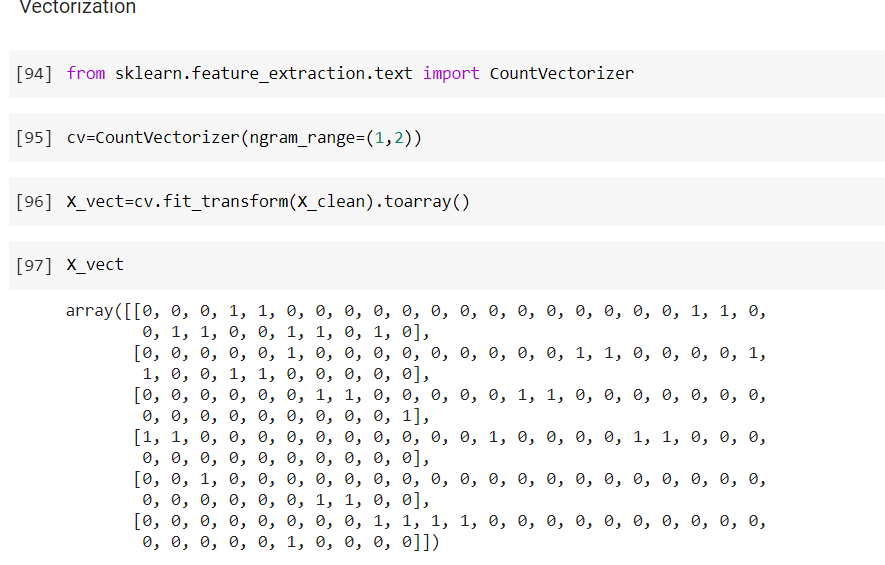 9. Feature Names help us to know that what the values 0 and 1 represent. It can be done using- Code Output  10. Now to perform text classification, we will make use of Multinomial Na�ve Bayes- Code Output 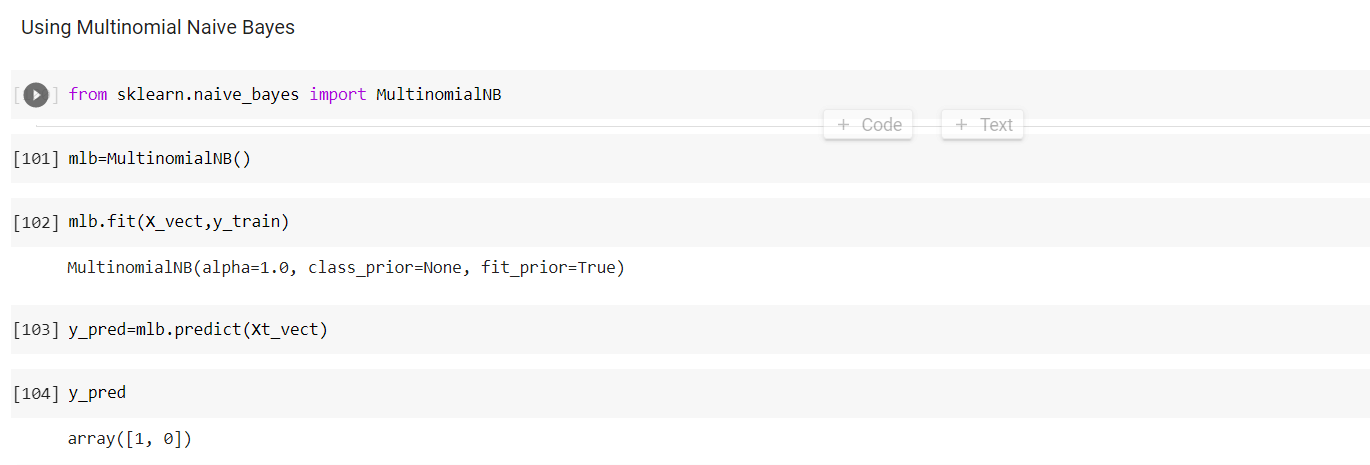 On prediction, it gives us the result in the form of array[1,0] where 1 denotes positive in our test set and 0 denotes negative. So, in this article, we discussed the pre-requisites for understanding Sentiment Analysis and how it can be implemented in Python. Next Topic# |











We provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India




