Real-Time Data Analysis from Social Media Data in Python This tutorial outline:
Global and Local PatternsEven though we may not be Twitter enthusiasts, we must realize that it significantly impacts the globe. In addition to being rich in insights, Twitter data offers near real-time monitoring of Twitter storms. This implies that we may pick up on the global thinking and emotion waves as they emerge. As with any location where there are riches, security personnel on Twitter are preventing us from immediately accessing the data to use their application programming interfaces (APIs) for data collecting; several authentication procedures must be followed. We already have a green--pass from security because our objective today is to learn how to extract insights from data. In the datasets folder, where our data is available, Twitter offers local and global trends. Let's load and examine data for subjects trending globally and in us at the time of the query - an example of a JSON response from a call to Twitter's GET trends /place API. Social Media DatasetImporting the appropriate Python libraries and using the right dataset will allow us to begin Real-Time data analysis from social media data Using Python . Main table (for reference only):
Reading the DataSource Code Snippet Prettifying the expected outputWe needed help--to--read data! Fortunately, we can use Jason.dumps() function to format it into a likely JSON string. Source Code Snippet Output: W W trends: [{'trends': [{'name': '#BeratKandili', 'url': 'http: / /twitter.com /search?q= % 43BeratKandili', 'promoted__content': None, 'query': ' % 43BeratKandili', 'tweet__volume': 46373}, {'name': '#GoodFriday', 'url': 'http: / /twitter.com /search?q= % 43GoodFriday', 'promoted__content': None, 'query': ' % 43GoodFriday', 'tweet__volume': 81891}, {'name': '#WeLikeTheEarth', 'url': 'http: / /twitter.com /search?q= % 43WeLikeTheEarth', 'promoted__content': None, 'query': ' % 43WeLikeTheEarth', 'tweet__volume': 159698}, {'name': '#195TLdenTTVeril: None, 'query': ' % E6 % B1 % A0 % E8 % A4 % 8B % E3 % 81 % AE % E4 % BA % 8B % E6 % 95 % 85', 'tweet__volume': 34381}, {'name': '????', 'url': 'http: / /twitter.com /search?q= % E3 % 83 % 97 % E3 % 83 % AA % E3 % 84 % A6 % E3 % 84 % B9', 'promoted__content': None, 'query': ' % E3 % 83 % 97 % E3 % 83 % AA % E3 % 84 % A6 % E3 % 84 % B9', 'tweet__volume': 44944}, {'name': 'Hemant Karkare', 'url': 'http: / /twitter.com /search?q= % 44Hemant+Karkare % 44', 'promoted__content': None, 'query': ' % 44Hemant+Karkare % 44', 'tweet__volume': 44067}}]
Finding the similar trendsWe can see from the attractively printed results (the output of the preceding task) that:
The two trends may be quickly skimmed over to identify shared patterns, but let's avoid making a "manual" effort. We may loop through the two tendencies objects, turn the lists of individuals to sets, and then execute the intersection function to obtain the names shared by the two sets using Python's set data structure. Source Code Snippet Output: {'# BLACKPINKxCorden', '東京・池袋衝突事故', '# ViernesSanto', '# Karfreitag', '# AFLNorthDons', '# HardikPatel', '# NRLBulldogsSouths', 'Lyra McKee', '# DuyguAsena', '�rg�tde?il arkada?grubu', 'Shiv Sena', '# يوم__الجمعه', 'プリウス', '# TheJudasInMyLife', '# ConCalmaRemix', '# DragRace', '重体の女性と女児', '# WeLikeTheEarth', 'Derry', 'Lil Dicky', '# ShivSena', 'Derrick White', 'Priyanka Chaturvedi', '# KpuJanganCurang', '# BeratKandili', '# Hay?rl?Cumalar', '# HanumanJayanti', '# CHIvLIO', '# Jersey', '# DinahJane1', '# JunquerasACN', '브이알',
{'# BLACKPINKxCorden', 'Seth Abramson', '# WorldofWarcraftMains', '# MakeAMovieSensual', '# AFLNorthDons', 'Kevin Durant', '# WGAMIX', '# NRLBulldogsSouths', '# GSWvsLAC', 'Lyra McKee', 'Mike Anderson', 'Oshie', '# WhatStopsYouFromGoingHome', '# FridayFeeling', '# GossipShouldBe', '# StarTrekDiscovery', 'David Fletcher', '# TimeToImpeach', 'Tomas Hertl', 'Silky', '# ConCalmaRemix', '"Earth"', '# TheLegendOfVoxMachina', '# DragRace', '# LilDicky', 'Derry', '# WeLikeTheEarth', 'Lil Dicky', '# MyInnerDemonSaid', 'WE LIKE THE EARTH', 'Derrick White', 'Yvie', '# RPDR', 'Gallant', 'Lone Wolf and Cub', '# DinahJane1', '# HustleAndSoul', '# fridaymotivation', '# MyDrunkUncleSays', '# CUZILIKEYOU', 'Shy Glizzy', 'George Conway', 'Servais', '# CriticalRoleSpoilers', '# WeirdDateStories', '# DontChangeOutNow', '# Earth', 'Kazuo Koike', '# rupaulsdragrace', 'Game 6'}
11 common trends: {'# BLACKPINKxCorden', 'Derrick White', '# AFLNorthDons', '# NRLBulldogsSouths', 'Lyra McKee', '# ConCalmaRemix', '# WeLikeTheEarth', '# DinahJane1', '# DragRace', 'Derry', 'Lil Dicky'}
Hot Trend ExplorationOut of the two collections of trends (each of size Fifty), we can observe from the intersection (final output) that there are 11 overlapping subjects. One prevalent tendency, in particular, seems quite intriguing: It's encouraging to see everyone on Twitter expressing their liking for Mother Earth with the hashtag #WeLikeTheEarth. When we ran the query to gather the trends, folks in us were enraged about things that only applied to them, so we had little or a far larger overlap. Source Code Snippet Explanation: We've discovered a trend: #WeLikeTheEarth. Let's check out the narrative it is yelling at us to tell now! With the hashtag in question as a query parameter, we can retrieve messages connected to it through Twitter's search API. The 'WeLikeTheEarth.json' file that the search API returned is what we have saved there. So let's load this data set and investigate this pattern in more detail. Source Code Snippet Output: [{'contributors': None,
'coordinates': None,
'created__at': 'Fri Apr 19 08:46:48 +0000 4019',
'entities': {'hashtags': [{'indices': [30, 45], 'text': 'WeLikeTheEarth'}],
'symbols': [],
'urls': [{'display__url': 'youtu.be /pvuN__WvF1to',
'expanded__url': 'https: / /youtu.be /pvuN__WvF1to',
'indices': [46, 69],
'url': 'https: / /t.co /L44XsoT5P1'}],
'user__mentions': [{'id': 1409516660,
'id__str': '1409516660',
'indices': [3, 18],
'name': 'LD',
'screen__name': 'lildickymessages'}]},
'favorite__count': 0,
'favorited': False,
'geo': None, 'id': 1119160405470543904,
'id__str': '1119160405470543904', 'in__response__to__screen__name': None,
'in__response__to__status__id': None, 'in__response__to__status__id__str': None,
'in__response__to__user__id': None, 'in__response__to__user__id__str': None,
'is__quote__status': False, 'lang': 'en',
'metadata': {'iso__language__code': 'en', 'result__type': 'recent'}, 'place': None,
'possibly__sensitive': False,
'retweet__count': 7484, 'retweeted': False, 'retweeted__status': {'contributors': None, 'coordinates': None, 'created__at': 'Fri Apr 19 04:44:49 +0000 4019',
'entities': {'hashtags': [{'indices': [10, 45], 'text': 'WeLikeTheEarth'}],
'symbols': [], 'urls': [{'display__url': 'youtu.be /pvuN__WvF1to',
'expanded__url': 'https: / /youtu.be /pvuN__WvF1to', 'indices': [46, 49],
'url': 'https: / /t.co /L44XsoT5P1'}], 'user__mentions': []},
'favorite__count': 13317, 'translator__type': 'none',
'url': 'https: / /t.co /aFrPkkJKqs', 'utc__offset': None,
'verified': True}},
'source': '<a href="http: / /twitter.com /download /android" rel="nofollow">Twitter for Android< /a>',
'text': 'RT @lildickymessages: ? out now #WeLikeTheEarth https: / /t.co /L44XsoT5P1', 'truncated': False,
'user': {'contributors__enabled': False,
'created__at': 'Fri Nov 05 44:45:49 +0000 4010',
'default__profile': False,
'default__profile__image': False,
'description': "''you just got knocked the fuck out''",
'entities': {'description': {'urls': []},
'url': {'urls': [{'display__url': 'likeeeujdb.tumblr.com',
'expanded__url': 'http: / /likeeeujdb.tumblr.com /',
'indices': [0, 43]}]
Digging more deeperPrinting the initial two message items helps us realize that a message is much more than simply a brief text message, which is how we often conceive of them. Let's stay calm by the volume of data in a message object! See if we can uncover ideas by concentrating on a few fascinating subjects. Source Code Snippet Output: [ "RT @lildickymessages: \ ud83c \ udf0e out now #WeLikeTheEarth https: / /t.co /L44XsoT5P1", " \ ud83d \ udc9a \ ud83c \ udf0e \ ud83d \ udc9a #WeLikeTheEarth \ ud83d \ udc47 \ ud83c \ udffc", "RT @cabeyoomoon: Ta piosenka to bop, wpada w ucho i dochody z niej id \ u0105 na dobry cel, warto s \ u0144ucha \ u0107 w k \ u00f3 \ u0144ko i w k \ u00f3 \ u0144ko gdziekolwiek si \ u0119 ty \ u4046", "#WeLikeTheEarth \ nCzemu ja si \ u0119 pop \ u0144aka \ u0144am", "RT @Spotify: This is epic. @lildickymessages got @justinbieber, @arianagrande, @halsey, @sanbenito, @edsheeran, @SnoopDogg, @ShawnMendes, @Kr \ u4046", "RT @biebercentineo: Justin : are we gonna die? \ nLil dicky: you know bieber we might die \ n \ nBTCH IM CRYING #EARTH #WeLikeTheEarth #WELIKEEART \ u4046", "RT @dreamsiinflate: #WeLikeTheEarth \ u401ci am a fat fucking pig \ u401d okay brendon urie https: / /t.co /FdJmq31xZc", "Literally no one: \ n \ nMe in the past 4 hours: \ n \ nI'm a koala and I sleep all the time, so what, it's cute \ ud83c \ udfb6 \ n \ n#WeLikeTheEarth #EdSheeranTheKoala", "RT @Yuuupthatsme: Mia \ u0144e \ u015b by \ u0107 \ u017cyraf \ u0105 #WeLikeTheEarth https: / /t.co /0kNCpU8o6q", "RT @jaguareffects: eu prestando aten \ u00e7 \ u00e3o no \ u00e1udio pra identificar cada artista \ n \ n#WeLikeTheEarth https: / /t.co /0cDtiV4t1E" ] Frequency analysisWe may infer the following from the first five results of the most recent extraction:
We got a feel of the data by looking at the top 10 items in the interesting fields. Now that we've completed a straightforward but crucial exercise, calculating frequency distributions, we can look closer. Starting with frequencies is a good idea since it gives you ideas for moving forward. Source Code Snippet Output: [('lildickymessages', 104) , ('LeoDi' , 44) , ('ShawnMendes' , 33) , ('Halsey , 31) , ('ArianaGrande' , 30) , ('Justin Bieber , 49) , ('Spotify' , 46) , ('edsheeran' , 46) , ('sanbenito' , 45) , ('SnoopDogg' , 45)]
[('WeLikeTheEarth' , 313) , ('4future' , 14) , ('19aprile' , 14) , ('EARTH' , 11) , ('fridaysforfuture' , 10) , ('EarthMusicVideo' , 3) , ('ConCalmaRemix' , 3) , ('Earth' , 3) , ('aliens' , 4) , ('AvengersEndgame' , 4)]
Activity more about the trendWe may further develop our conclusions based on the most recent frequency distributions:
We may determine how popular a message is by examining the favorite count and retweet count data. With so many celebrities in the photo, can we determine whether their support for #WeLikeTheEarth affected a sizable fraction of their followers if we additionally extract the tweeter's follower count? The total amount of times the initial message was retweeted is provided by the retweet__count field. Both the initial message and any subsequent re-test should have the same information. To get your mind around the many fields, play around with some sample messages and the official documentation. Source Code Snippet A table that speaks thousands of wordsLet's modify the data and make it richer and better looking since "looks matter!" Source Code Snippet Analyzing all the above-used languagesAccording to our table, Lil Dicky's followers responded the most; 44.4% liked his initial tweet.
In addition, the fact that this was Lil Dicky's music video may have contributed to the stark contrasts in responses. Due to his significant contribution to this campaign, Leo still gained more traction than Katy or Ellen. Can the data be analyzed for any more intriguing patterns? We could distinguish several languages from the text of the messages, so let's make a frequency distribution for each. Source Code Snippet Output: 107. , 44. , 14. , 36. , 34. , 3. , 4. , 1. , 4.]) , array([ 0. , 1.3 , 4.6 , 3.4 , 5.4 , 6.5 , 7.8 , 4.1 , 10.4 , 11.7 , 13. ]), <a list of 10 Patch objects>) (array([303. , 107. , 44. , 14. , 36. , 34. , 3. , 4. , 1. , 4.]) , array([ 0. , 1.3 , 4.6 , 3.4 , 5.4 , 6.5 , 7.8 , 4.1 , 10.4 , 11.7 , 13. ]), <a list of 10 Patch objects>) 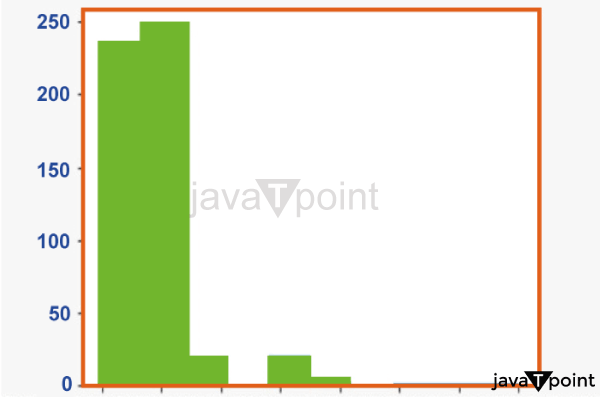 Summary: Find thoughtsThe final histogram reveals that: The majority of messages were in English, while the next three most popular languages were Polish, Italian, and Spanish. There were several messages in an unrelated language to Facebook (lang = "und"). Why is this kind of knowledge helpful? It can help us understand the "category" of people interested in this subject (clustering). To address inquiries such as, "Does owning an iPhone compared to Android influence the tendency of individuals towards this trend?" we may additionally analyze the device type used among the Twitteratis tweets. I'll leave you with it as a new workout! What a thrilling adventure it has been! We have come a long way from virtually complete ignorance when we first began. We have covered much today, from location-based comparisons to analyzing message activity to discovering patterns across languages and devices. Let's give ourselves a deserved pat on the back! Next TopicException handling in Python |











We provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India




