Q-Learning in PythonReinforcement learning is a model in the Learning Process in which a learning agent develops, over time and in the best way possible within a particular environment, by engaging continuously with the surroundings. During the journey of learning, the agent will encounter different scenarios in the surroundings it's in. They are known as states. The agent in the state can select from a variety of permissible actions, which can result in various rewards (or punishments). The agent who is learning over time develops the ability to maximize these rewards to perform optimally in any condition it is in. Q-Learning is a fundamental type of reinforcement learning that utilizes Q-values (also known as action values) to improve the learner's behaviour continuously. - Q-Values, also known as Action-Values:Q-values are defined for actions and states. Q(S A, S) is an estimate of the probability of performing the action at the time of S. The estimation of Q(S A, S) is computed iteratively by using the TD-Update rule that we will learn about in the coming sections.
- Episodes and Rewards:An agent, throughout his life, begins in a state of beginning and makes numerous shifts between its present state and the next state, according to the type of actions and the environment it interacts with. Every step in the transition, an agent in the state of transition takes action, is rewarded by the surrounding environment then goes to a new state. In the event that, at some point in time, the agent lands at one of the ending states, it means that there are no more transitions that are feasible. This is referred to as the end of an episode.
- Temporal Difference or TD-Update: A temporal Difference (TD) Update rule could be expressed in the following manner:
Q(S,A)←Q(S,A)+ α(R+ γQ(S`,A`)-Q(S,A)) - The update rule used to calculate Quantity is used each time stage of the Agent's interaction with their environment. The terminology used is explained below:
- S: The current state of the Agent.
- A: The current Action is selected by a policy.
- S`: Next State where the Agent will end up.
- A`: The next most effective option to choose based on the most current Q-value estimation, i.e., select the Action that has the highest Q-value in the following state.
- R: Current Reward was seen by the environment in response to current actions.
- γ(>0 and <=1): Discounting Factor for Future Rewards. Future rewards are of lesser value than present rewards. Therefore they should be discounted. Because the Q-value estimates anticipated rewards from a specific state, the discounting rules are also applicable in this case.
- α: The length of a step to revise Q(S, A).
- Making the Action to undertake using the ϵ-gracious policy: The ϵ-greedy strategy is a simple method of selecting actions based on the most current estimations of Q-values. The policy is according to the following:
- With a probability (1 - ϵ), pick the option with the most Q-value.
- With a high probability (ϵ), pick any choice at random.
With all the knowledge needed, let's use an example. We will utilize the gym environment created by OpenAI to build the Q-Learning algorithm. Install gym: We can install gym, by using the following command: Before beginning with this example, we will need an helper code to see the process algorithm. Two helper files need to be downloaded from our working directory. Step 1: Import all the required libraries and modules. Step 2: We will instantiate our environment. Step 3: We have to create and initialize the Q-table to 0. Step 4: We will build the Q-Learning Model. Step 5: We will train the model. Step 6: At last, we will Plot important statistics. Output: 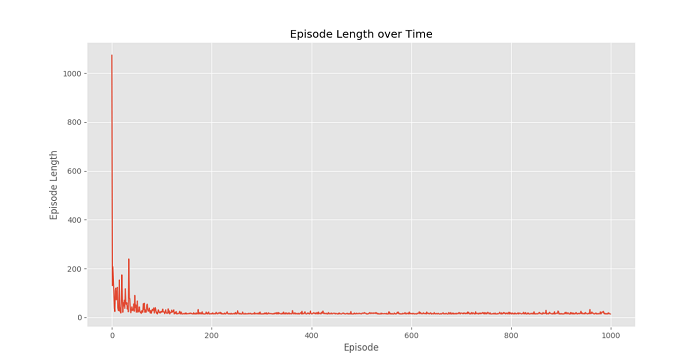
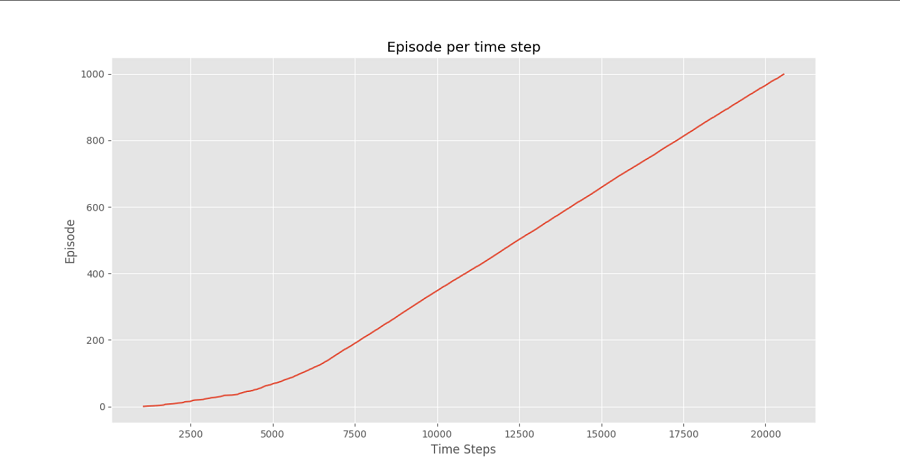
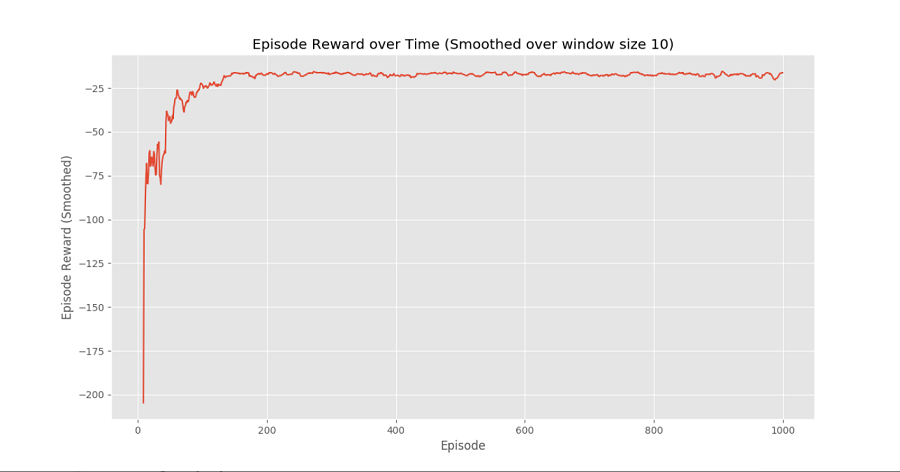 ConclusionWe can see in the Episode Reward Over Time plot that the rewards for each episode are gradually increasing in time until it gets to a point at a high reward per episode, which suggests that this agent learned to maximize the total reward in each episode by exhibiting optimal behaviour in each and every level.
|















