Python Bio ModuleMost of us have thought about why Python is growing so much rapidly when we compare it with other programming languages? Yes, Python indeed got famous in a very short span of time, and now we can see applications of Python in every field. And, yes, every field means every field where technology can be seen. Python programming language is not only limited to programming or developing purpose, and now we can also see the use of it in various other fields like medical, business, defence, e-commerce etc. The major reason behind Python's huge development and reach is its simplicity, and numerous libraries come with it. Many fields are achieving a new height of success and development just because of the use of Python in them. If we look again at the names of fields we have mentioned, we will find that we have also mentioned the medical field. Now, many of us will think that how Python can be helpful in the medical field. The answer to this question is not only limited to medical equipment used in a hospital or in a clinic but Python is also used in various other fields of medicine. One important field of medicine where Python can be seen is Bioinformatics, and we don't have to get confused here between genetics (which is Biotechnology) and bioinformatics. Note: Bioinformatics is an interdisciplinary field that includes studies from biology and various other fields such as computer science, mathematics, physics, etc.In Python, we have a very famous module, Biopython, for bioinformatics, and the use of this module is rapidly increasing as many scientists are now using this module for their research. In this tutorial, we are going to study this Biopython module and learn a bit about it. We will also learn about its installation and how it is used for research work in bioinformatics through an example. Biopython ModuleIn Python or even in most programming languages, Biopython is not just the most popular but also the largest bioinformatics package. Biopython Module contains a lot of different sub-packages for performing common bioinformatics tasks. The Biopython module is mainly written in Python, but it also contains C code, and Chang and Chapman developed it. The C code present in the Biopython package is used to optimize the complex computation part of the module. The Biopython can run on multiple operating systems such as Windows, Linux, UNIX, Mac OS X, etc. Before we start learning about Biopython Module, we must have a basic idea of bioinformatic terms such as DNA, RNA, protein sequences, genome sequences etc. Otherwise, it won't be easy to understand the working and functions of this module. Besides the basic terms of bioinformatics, we should make sure that the latest version of Python is present in our system and we are familiar with the pip installer. Biopython Module: IntroductionThe Biopython Module is a collection of different Python modules which provides many different functions to deal with various genetic structures such as DNA, RNA and protein sequence operations. The protein sequence operations we mentioned here can be finding motifs in protein sequence, reverse complementing of a DNA sequence, etc. In Biopython Module, we are provided with a lot of parsers and with the help of these parsers, we can read all the major genetic databases such as SwissPort, GenBank, FASTA, etc. These parsers are also very helpful in reading major wrappers/interfaces, which are very helpful in running other popular bioinformatics tools/software like Entrez, NCBI BLASTN etc. With the help of the Biopython Module, we can do all this inside a Python environment using a Python program. Biopython Module: FeaturesTill now, we surely have an idea of how important the Biopython Module is and how it is helpful for all those who are related to the Bioinformatics field. Now, we will discuss the features that Biopython Module offers and for which it is famous. Following is the list of salient features of the Biopython Module:
We have now seen all the salient features of the Biopython Module, and now we can understand how useful this module is for all the work done in the bioinformatics field. Biopython Module: GoalsAs we all know, that Biopython Module is the best Python package for all fieldwork and research work in bioinformatics, but there would have been some goals for what this package was built. If we talk in general, Biopython Module was built with the goal to provide standard yet simple and extensive access to all the data and tools required for bioinformatics work through Python language. But this wasn't the only goal of building this module; there were other major goals too. We will discuss all these major goals for which the Biopython module was built and list them in this section. Following is the list of all the major or specific goals for building Biopython Module:
So, these are all the specific and major goals for which Biopython Module was built and introduced in Python as a package for bioinformatics. Biopython Module: AdvantagesWe have now seen the features of the Biopython Module and how it can be very helpful to all of those connected with the field of bioinformatics. We can easily depict some of the advantages of this module, but still, there are some advantages that we can't guess with the listed features or goals. Therefore, in this section, we will see all the advantages of the Biopython Module and how it is helpful in many ways. Following are some of the advantages of using the Biopython Module for all the studies and work related to Bioinformatics:
So, this is the list of all the advantages we have when we use Biopython Module, and it also depicts how this module is very helpful and useful for everyone connected with the field of bioinformatics. Biopython Module: InstallationNow, we will learn about its implementation and its functioning in a Python program. We have to first install the Biopython Module in our system, and then only we will be able to import and use functions of this module in a Python program. Therefore, we will learn here about the installation process of the Biopython Module in our system, and we will also check the compatibility of Python installed in our device. This is because Biopython Module is supported in Python version above or equal to 2.5, and Python having version lesser than 2.5 do not support installation and importing of Biopython Module. That's why first we should make sure that Python installed in our system is of higher requisite or latest versions. Now, if we don't know the version of Python installed in our system and we want to check it, then we can use the following command in the command prompt terminal: When we press the enter key, the version of Python installed in our system will be displayed, as we can see in the output image. 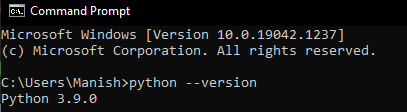 In the displayed version, we can see that version of Python installed in the system is higher than the required version. But if somehow the version of Python present in our system is not equal to or higher than the required version, i.e., Python version 2.5, then we should first update it and then only we can proceed with the installation part. Note: There are many other ways to check the version of Python installed in our system, but we will prefer this one to use as this is the easiest and simplest method.Now, after checking the version of Python installed in our system, we will look forward to installing the Biopython module, and we will use the pip installer to install this module. We will use the following pip installer command in the command prompt terminal to install the Biopython Module in our system: When we press the enter key after writing the command, the pip installer will start installing the Biopython Module in our system. 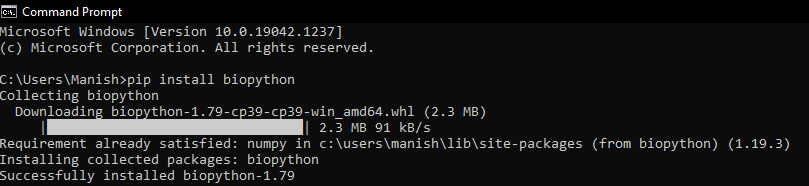 Biopython Module is now successfully installed in our system, and now we can import it into a Python program to use its functions and learn its implementation. Biopython Module: ImplementationTo learn how the Biopython Module works and how it helps in parsing bioinformatics files, we have first to create a sample FASTA file (Here 'fasta' is referred to the file format sequence originated from the bioinformatics software). In FASTA file format, the sequence in the file is arranged one by one, and each sequence present in the file will have its own ID, name, description and actual sequence data. We will first have to open notepad present in our system and write down the following content in it:  Now, we have to save this notepad file with the name 'SampleFile1.fasta', and we have to save this in the same directory where Python is installed so that we don't have to write the whole directory while opening the file. It's time that we will use Biopython Module in a Python program and learn its implementation by parsing the sample fasta file we created. Look at the following Python program where we have parsed the sample fasta file using functions of Biopython Module: Output: Id of FASTA File: sampleFile|P2426|FMS1_ECOLI
Name of FASTA File: sampleFile|P2426|FMS1_ECOLI
Description of FASTA File: sampleFile|P2426|FMS1_ECOLI CS1 is a fimbrial subunit of the precursor (Have CS1 pilin)
Annotations in FASTA File: {}
Sequence Data in FASTA File: MKLKKTIGADALATLFATMGASAVEKTISVTASVDMTVDLLQSDGSALPNSVALTYSPAVNNFEAHTINTVVQTNDSDKGVVVKLSAMPVLSNVLNPTLQIPVSVNFAGKPLSTTGITIDSNDLNFASSGVNKVSMTQKLSIHADATRVTGGALTAGQYQGLVSIILTKSTTTTTTTKGT
Id of FASTA File: sampleFile|P2631|FMS3_ECOLI
Name of FASTA File: sampleFile|P2631|FMS3_ECOLI
Description of FASTA File: sampleFile|P2631|FMS3_ECOLI CS3 is a fimbrial subunit of the precursor (Have CS3 pilin)
Annotations in FASTA File: {}
Sequence Data in FASTA File: MLKIKYLLIGLSKSAMSSYSLAAAGPTLTKELALTVLSPAALDATWAPQDNLTLSNTGVSNTLVGVLTLSNTSIDTVSIANTNVSDTSKNGTVTFAHETNNSASFATTISTDNANITLDKNAGNTIVKTTNGSPLPTNLPLKFITTEGNEHLVSGNYRANITITSTIKGGGTKKGTTDKK
Explanation: We have firstly imported the different tools of the Biopython Module in the program, such as parse, SeqRecord and Seq, using the 'from' keyword. Then, we opened the sample fasta file we created in the program using the open() function. After that, we have used the parse() function on the variable we initialized to open the sample file, i.e., sampleFile. Then, we looped over the parseRecords variable (Initialized variable where file parsed) to print the different properties and attributes from the file. We have displayed the following attributes with their respective functions of the Biopython Module:
As we can see in the output, all the attributes of the sample fasta file are successfully printed, and these attributes are printed for the first sequence firstly and then for the second sequence. This is a sample file example that how we can use Biopython Module in the bioinformatics work and how it helps parse bioinformatics software files using a Python program. Next TopicPython Dash Module |











We provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India




