Keras ModelsKeras has come up with two types of in-built models; Sequential Model and an advanced Model class with functional API. The Sequential model tends to be one of the simplest models as it constitutes a linear set of layers, whereas the functional API model leads to the creation of an arbitrary network structure. Keras Sequential ModelThe layers within the sequential models are sequentially arranged, so it is known as Sequential API. In most of the Artificial Neural Network, the layers are sequentially arranged, such that the data flow in between layers is in a specified sequence until it hit the output layer. Getting started with the Keras Sequential modelThe sequential model can be simply created by passing a list of instances of layers to the constructor: The .add() method is used to add layers: Specifying the input shapeSince the model must be aware of the input size that it is expecting, so the very first layer in the sequential model necessitates particulars about its input shape as the rest of the other layers can automatically speculate the shape. It can be done in the following ways:
These are the following snippets that are strictly equivalent: CompilationAt first the model is compiled for which the compile process is used for constructing the learning procedure afterward the model undergoes the training in the next step. The compilation include three parameter, which are as follows:
TrainingThe Numpy arrays of input data or labels are incorporated for training the Keras model and so it make use of fit function. Example: Training a simple deep learning Neural Network on the MNIST dataset Stacked LSTM for Sequence ClassificationTo make model capable enough to learn high-level temporal representation, 3 LSTM layers are stacked on above one another. The layers are stacked in such a way that first two layers yields complete sequences of output and the third one produces final phase in its output sequence, which helps in successful transformation of input sequence to the single vector (i.e. dropdown of temporal dimension). 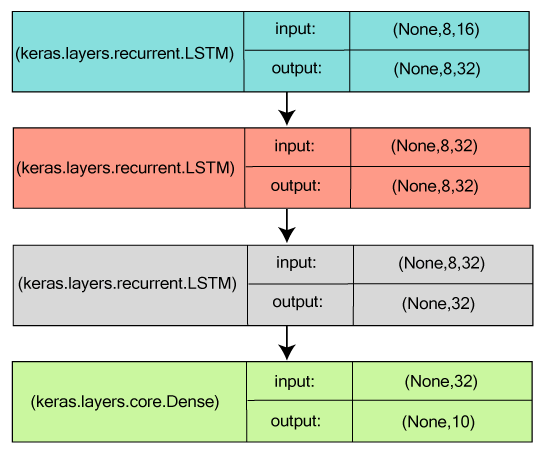 Same Stacked LSTM model, rendered "stateful"A model whose central (internal) states are used again as initial states for another batch's sample, which were acquired after a batch of samples were processed is called as a 'stateful recurrent model'. It not only manages the computational complexity but also permit to process longer sequence. Keras Functional APIKeras Functional API is used to delineate complex models, for example, multi-output models, directed acyclic models, or graphs with shared layers. In other words, it can be said that the functional API lets you outline those inputs or outputs that are sharing layers. First Example: A densely-connected networkTo implement a densely-connected network, the sequential model results better, but it would not be a bad decision if we try it out with another model. The implementation of Keras Functional API is similar to that of the Keras Sequential model.
All models are callable, just like layersSince we are discussing the functional API model, we can reuse the trained models simply by treating any such model as if it is a layer. It is done by calling a model on a tensor. When we call a model on tenor, it should be noted that we aren't only reusing its architecture but its weights too. The code given above allows an instance to build a model for processing input sequences. Also, with the help of an individual line, we can convert an image classification model into a video classification model. Multi-input and multi-output modelsSince functional API explains well multi-input and multi-output models, it handles a large number of intertwined datastreams by manipulating them. Let us look at an example given below to understand more briefly about its concept. Basically, we are going to forecast how many retweets and likes a news headline on social media like twitter will get. Both the headline, which is a sequence of words, and an auxiliary input will be given to the model that accepts data, for example, at what time or the date the headline got posted, etc. The two-loss functions are also used to oversee the model, such that if we use the main loss function in the initial steps, it would be the best choice for regularizing the deep learning models. 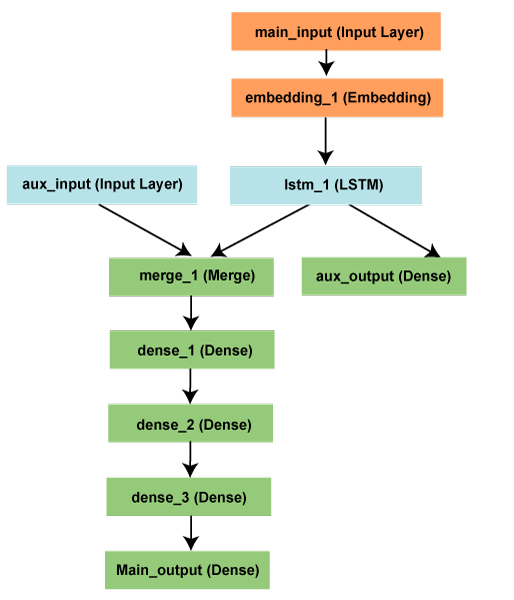 Here the main_input obtains the headline as a sequence of integers for which each integer will encode each word. The integers are in a range from 1 to 10,000, and the sequences are of 100 words. Then the auxiliary loss will be inserted that will permit the LSTM and Embedding layer to train itself smoothly even when the main loss in the model is higher. Next we will input the aux_input to our model, which is done by concatenating it with LSTM output. Thereafter, we will compile our model by assigning 0.2 weight on the auxiliary loss. And then we will use a list or a directory to identify the loss or loss_weight for all of the distinct outputs. To use same loss on every output, a single loss argument (loss) will be passed. Next we will train our model by passing a lists of an input array as well as target arrays. As we have named inputs and outputs, the model will be compiled as follows; The model can be inferenced by; or, Shared layersAnother example to be taken into consideration to understand the functional API model would be the shared layers. For this purpose, we will be examining the tweet's dataset. Since we are willing to compose such a model that can determine if two tweets belong to the same person or not, this will make it easy for an instance to compare users based on the similarities of tweets. We will construct a model that will go through the encoding of two tweets into vectors, followed by concatenating them, and then we will include logistic regression. The model will output a probability for two tweets belonging to the same person. Next, we will train our model on pairs of both positive as well as negative tweets. Since here our chosen problem is symmetric, our mechanism must reuse the first encoded tweet so as to encode the other tweet for which we will be using a shared LSTM layer. To build this model with a functional API, we will input a binary matrix of shape (280,256) for a tweet. Here 280 is a vector sequence of size 256, such that each 256-dimensional vector will encode the presence or absence of a character. Next we will input a layer and then will call it on various inputs as per the requirement, so that we can share a layer on several inputs. Now to understand how to read the shared layer's output or output shape, we will briefly look at the concept of layer "node". At the time of calling a layer on any input, we are actually generating new tensor by appending a node to the layer and linking the input tensors to the output tensor. If the same layer is called several times, then that layer will own so many nodes, which will be indexed as 0,1,2,.. To get the tensor output of a layer instance, we used layer.get_output() and for its output shape, layer.output_shape in the older versions of Keras. But now get_output() has been replaced by output. The layer will return one output of the layer as long as one layer is connected to a single input. In case if the layer comprises of multiple inputs; Output: >> AttributeError: Layer lstm_1 has multiple inbound nodes, hence the notion of "layer output" is ill-defined. Use `get_output_at(node_index)` instead. Now the following will execute it; So, the same carries for characters such as input_shape and output_shape. If a layer comprises of individual layer or all the nodes are having similar input/output, only then we can say that the conception of "layer input/output shape" is completely defined and the shape will be return by layer.output_shape/ layer.input_shape. In case if we apply conv2D layer to an input of shapes (32, 32, 3) and then to (64, 64, 3), then the layer will encompass several shapes of input/output. And to fetch them we will require to specify the index of nodes to which they belong to. Next TopicKeras layers |











We provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India




