How to read HTML table in PythonIn this tutorial, we will learn to read the HTML table using Python. As we know, a large amount of data is produced daily and we need to extract the relevant information. The internet is a great source of getting relevant data to our requirements, and web scraping is one of the best options to collect data from the web. Moreover, Python makes web scrapping quite easier with the help of the BeautifulSoup module. We will use Python's pandas library, which is popular for data handling. It provides the read_html() function that helps to read HTML tables on the web pages in the form of a list of DataFrame objects. PrerequisitesTo read the HTML file using Python script, we need to install the pandas library. Once the library is installed, we also need the lxml module to use the read_xml() function. We can install it using the below command. Exacting tables from a string of HTML using PythonIn the following example, we have created a simple HTML table and assigned into the html_table variable. Let's see the following example. Example - Now we will read the above HTML table. Output: [ ID Name Branch Result 0 5 Patrick Civil Pass 1 1 Maverick Mechanical Fail 2 4 Peter Computer Science Pass 3 8 Parker Chemical Fail] Explanation - In the above code, we used the pandas library in Python to parse an HTML table represented as a string. The pd.read_html() function is used to parse the table and return a list of dataframes, in this case, containing only one dataframe. The variable html_table contains a string representation of an HTML table with four columns: ID, Name, Branch, and Result. The table has a header row and four data rows. After calling the pd.read_html() function on html_table variable, the resulting dataframe will be stored in the variable df. The df variable can then be used to access the data in the table and manipulate it as needed. As we can see the output is in the form of list which containing only one table. We can use the indexing to view specific index in the list. 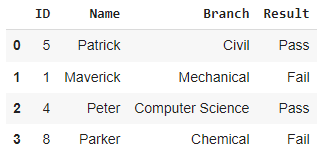 We can also check the data type of each column as below. Output: ID int64 Name object Branch object Result object dtype: object Getting Table Data from URLWe can also pass the URL as an argument in the read_html() function to read the HTML tables on the web page. Let's understand the following example. Example - Output: 0 1 2 0 Rank Country Area in sq. km 1 1. Russia 17098242 2 2. Canada 9984670 3 3. United States 9826675 4 4. China 9596961 5 5. Brazil 8514877 6 6. Australia 7741220 7 7. India 3287263 8 8. Argentina 2780400 9 9. Kazakhstan 2724900 10 10. Algeria 2381741 Note - The content of a web page can be varied over the time so that we may get different result.Extracting Tables from FilesWe can also read the table from the text file. We need to pass the filepath to the function. Let's understand the following example. Example - Output: [ ID Name Designation Salary
0 5 Peter HR 50000
1 1 Parker Salesperson 38000
2 4 Stark Analyst 85000
3 8 Falcon Software Developer 67000,
Roll No. Name Marks
0 10 Natasha 23
1 5 Bruce 40
2 18 Banner 44]
The above contains the two elements in the list. We can get each table using indexing. Output: ID Name Designation Salary 0 5 Peter HR 50000 1 1 Parker Salesperson 38000 2 4 Stark Analyst 85000 3 8 Falcon Software Developer 67000 Output: ID Name Designation Salary 0 5 Peter HR 50000 1 1 Parker Salesperson 38000 2 4 Stark Analyst 85000 3 8 Falcon Software Developer 67000 ConclusionThe read_html() is a useful and efficient method to read HTML tables from several source. It is very helpful while performing web scrapping. However, the read_html() method cannot read tables that loaded with JavaScript. |











We provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India




