Deploy a Machine Learning Model using Streamlit LibraryMachine Learning:Machine learning is the ability of a computer to learn from its experience, even if it has not been programmed. Machine Learning is a hot field right now, and many top companies around the globe are using it to improve their products and services. A Machine Learning model that is not trained in our Jupyter Notebook is useless. We need to make these models available for everyone so they can be used. In this tutorial we will train an Iris Species classification classifier and then deploy the model with Streamlit, an open-source app framework that allows us to deploy ML models easily. Understanding Streamlit Library:Streamlit allows us to create apps for our machine-learning project with simple Python scripts. Hot reloading is also supported, so our app can be updated live while we edit and save our file. Streamlit API allows us to create an app in a few lines of code (as we'll see below). Declaring a variable is the same thing as adding a widget. We don't need to create a backend, handle HTTP requests or define different routes. It's easy to set up and maintain. First, we will train the model. As the primary purpose of this tutorial, we will not be doing much pre-processing. Training the Model:Required Modules and Libraries: To begin, let's install the necessary modules and libraries by running the following commands: Dataset:Next, we need a dataset to train our model. In this tutorial, we will use the Iris dataset. Let's load the dataset and take a look at its structure: Code: Output: 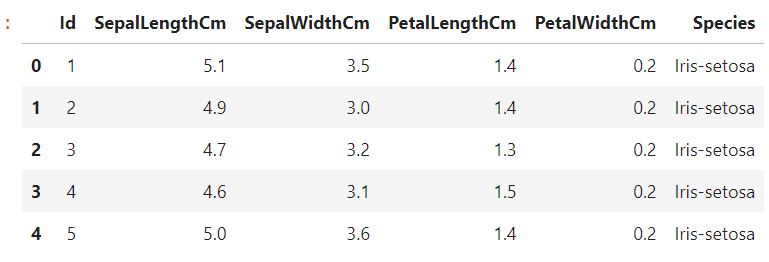 We will now drop the Id column as it is not necessary for Iris species classification. Next, we will divide the data into a training and testing set and use a Random Forest Classifier. Any other classifier can also be used, such as logistic regression or support vector machine. Code: Now, let's split the data into features (X) and the target variable (y). We'll use 70% of the data for training and 30% for testing: Code: For this tutorial, we'll utilize an Random Forest Classifier, yet go ahead and investigate different classifiers like logistic regression or support vector machines. We should prepare the model and assess its precision: Code: Output: Prediction Accuracy: 0.9777777777777777 As, we got the accuracy of 97.78%, which is quite good. Saving the Trained ModelTo use this model for predicting unknown data, we must save it. A pickle is a tool that serializes and deserializes a Python object structure. Code: A new file called "classifier1.pkl", will be created in the same directory. We can now use Streamlit to deploy our model - Deploying the Model with StreamlitNow, let's deploy our model using Streamlit. Create a new Python file and copy the following code: Code: Save the file with a .py extension. In your terminal, navigate to the directory containing the file and execute the following command to run the Streamlit app: Syntax: Output: 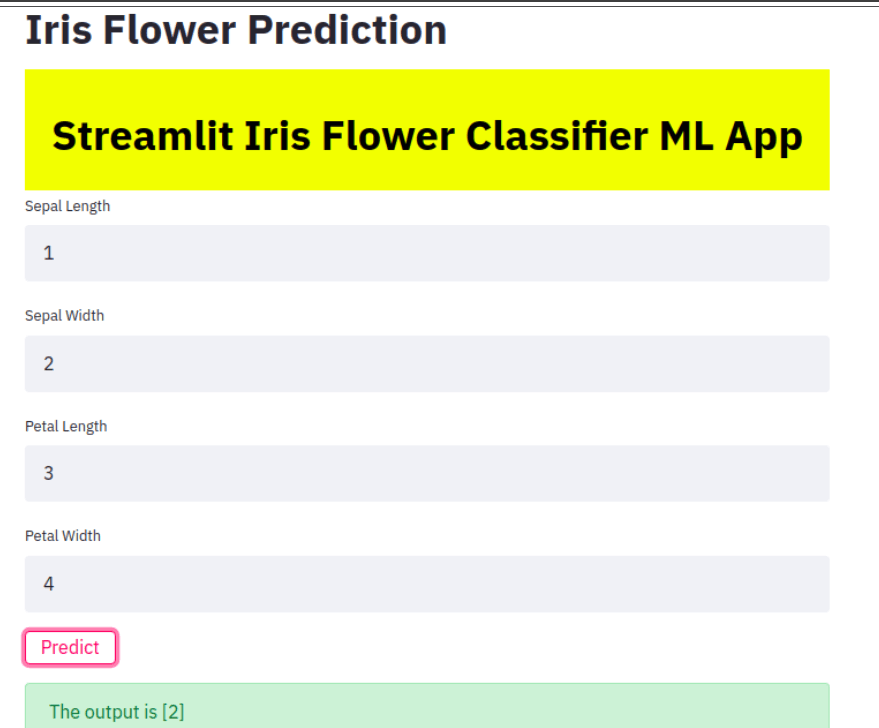 app1.py is where the Streamlit code was written. After the website opens in our browser, we can then test it. We can also use this method to deploy deep learning and machine-learning models. Conclusion:In this tutorial, we prepared an Irregular Timberland Classifier on the Iris dataset and sent the model utilizing the Streamlit library. We showed how to save the prepared model and make an intelligent web application for making expectations. Streamlit's effortlessness and strong elements go with it a superb decision for sending AI models. By following this tutorial, you can send your own models and make easy to use applications for others to profit from your AI arrangements. |











We provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India




