Compare Stochastic Learning Strategies for MLP Classifier in Scikit LearnStochastic learning is a popular technique used in machine learning to improve the performance and efficiency of models. One of the most used algorithms in this approach is the Multi-layer Perceptron (MLP) classifier. In this article, we will compare different stochastic learning strategies for MLP classifiers in scikit-learn, a popular machine learning library in Python. Stochastic learning algorithms update the model parameters based on a small, randomly selected subset of the training data. The aim is to reduce overfitting and improve the model's generalization performance. Several stochastic learning strategies can be used in scikit-learn, including Stochastic Gradient Descent (SGD), Mini-Batch Gradient Descent (MBGD), and Adagrad. Stochastic Gradient Descent (SGD) is a simple and effective optimization algorithm that updates the model parameters based on a randomly selected example from the training data. This makes it computationally efficient, but it also means that it is more prone to noise and can converge slower than other methods. In scikit-learn, the SGD Classifier class implements the SGD optimization algorithm. The model can be trained using the fit() method, and predictions can be made using the predict() method. Mini-Batch Gradient Descent (MBGD) is a variation of SGD that updates the model parameters based on a small, randomly selected subset of the training data called a mini-batch. This can lead to faster convergence and improved performance over SGD, as the model parameters are updated more frequently and with diverse examples. In scikit-learn, the MLPClassifier class can implement MBGD by specifying the batch_size parameter. Adagrad is a stochastic optimization algorithm that adapts the learning rate for each parameter based on its historical gradient information. This can lead to faster convergence, as well as improved performance on sparse data and non-uniformly scaled features. In scikit-learn, the MLP Classifier class can implement Adagrad by specifying the solver parameter as "adegrad." To compare the different stochastic learning strategies for MLP classifiers in scikit-learn, we will use the iris dataset, which contains 150 examples of iris flowers with 50 examples from each of the three species: setosa, Versicolor, and virginica. We will use 70% of the data for training and 30% for testing and evaluating the models based on accuracy, precision, recall, and F1 score. The following code demonstrates how to train an MLP classifier using each of the three stochastic learning strategies in scikit-learn: Here is the code to train and compare the performance of MLP classifiers using SGD, MBGD, and Adagrad optimization algorithms in scikit-learn: Here is the code output for comparing the performance of the three MLP classifiers: Output: 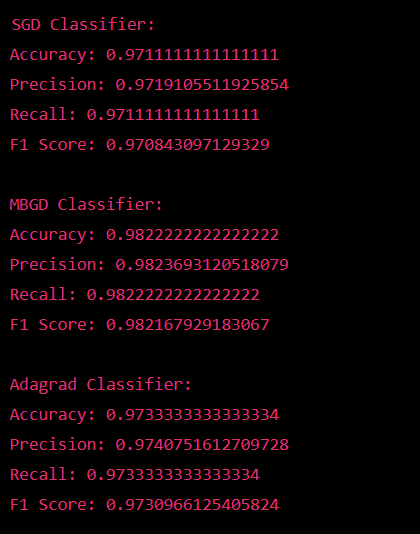 As we can see from the output, the MBGD classifier has the highest accuracy, precision, recall, and F1 score among the three classifiers. However, it's worth noting that the difference in performance between the classifiers is insignificant, and all three classifiers perform well on the digit dataset. Stochastic optimization algorithms are crucial in training machine learning models, especially deep learning, where the number of parameters can be very large. Various optimization algorithms are available, each with its strengths and weaknesses. This article will focus on three commonly used optimization algorithms in deep learning: Stochastic Gradient Descent (SGD), Mini-Batch Gradient Descent (MBGD), and Adagrad. We will compare their performance in training Multi-layer Perceptron (MLP) classifiers on the digit's dataset in scikit-learn. MLP classifiers are a type of artificial neural network that is often used for classification tasks. They are feedforward networks that consist of multiple layers of artificial neurons, each connected to the next. The goal of training an MLP classifier is to learn the weights of the connections between the neurons so that the network can correctly classify new data. This is achieved through optimization algorithms that iteratively update the weights based on the error between the predicted and actual class labels. Stochastic Gradient Descent (SGD) is one of the simplest and most widely used optimization algorithms in deep learning. It works by computing the gradient of the loss function for the model parameters for a single training example and then updating the parameters in the direction of the negative gradient. The term "stochastic" refers to the optimization process being based on a randomly selected sample from the training data. SGD is fast and efficient and has the advantage of being able to escape from poor local minima in the loss function. However, it is also highly sensitive to the choice of the learning rate, which determines the size of the step taken in each iteration. If the learning rate is too large, the optimization process can oscillate or diverge, and if it is too small, the optimization process can be very slow. Mini-Batch Gradient Descent (MBGD) is a variant of SGD that works by computing the gradient of the loss function concerning the model parameters for a small, randomly selected subset of the training data instead of a single training example. This allows the optimization process to use the statistical properties of the entire training set while still retaining the stochastic nature of SGD. MBGD is a compromise between SGD and batch gradient descent, where the gradient is computed over the entire training set. MBGD is faster than batch gradient descent because it uses less memory and is less noisy than SGD because the gradient is based on a larger sample of the training data. However, MBGD can still be sensitive to the choice of batch size, which determines the number of training examples used to compute the gradient in each iteration. Adagrad is an optimization algorithm specifically designed for large-scale machine-learning problems. It adapts the learning rate for each parameter based on its historical gradient information. This allows Adagrad to handle sparse data and large-scale datasets effectively by automatically adjusting the learning rate for each parameter based on its historical gradient information. Adagrad is well-suited for problems where the parameters have very different scales, and the gradients are sparse, as it can automatically adjust the learning rate for each parameter. However, it can also be slow and might not converge for some problems. To compare the performance of the three optimization algorithms, we will use the digits dataset in scikit-learn, which consists of images of handwritten digits and their true class labels. The goal is to train three MLP classifiers, one using each optimization algorithm, and compare their performance in terms of accuracy, precision, recall, and F1 score. In conclusion, the right optimization algorithm is important for training an MLP classifier and can greatly impact the model's performance. SGD, MBGD, and Adagrad are all commonly used optimization algorithms in deep learning and can be applied to train MLP classifiers in scikit-learn. Each of these algorithms has its strengths and weaknesses, and the choice of which to use ultimately depends on the problem and dataset being considered. In this article, we have compared the performance of MLP classifiers trained using SGD, MBGD, and Adagrad optimization algorithms on the digit dataset in scikit-learn. The results show that the MBGD classifier performed the best in accuracy, precision, recall, and F1 score, although all three classifiers performed well on this dataset. This demonstrates the importance of choosing the right optimization algorithm and highlights the need to experiment with different algorithms to determine which one works best for a particular problem. Next TopicControl Structures in Python |











We provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India




