Apply a Function to a Single Column of a CSV in SparkIntroduction:In this tutorial, we will discuss how we can apply a function to a single column of a csv in Spark. In the distributed computing system, Spark is used as an open-source system. Spark is used for data processing on a large scale and is very fast. It is used in various fields. But the most common use of Spark in a single CSV file column is that Spark applies a function of these files. Here we briefly elaborate on how to apply a function to a single column of a csv in Spark. Parameters of the Single Column of a CSV in SparkThe parameters of the single column of a csv in Spark are -
Syntax of the Single Column of a CSV in SparkThe syntax of the single column of a csv in Spark is - Working of Applying a Function to a Single Column of a CSV in SparkThe working of applying a function to a single column of a csv in Spark is that the rules or the transformation are fully user defined. It is applied to a column in the data set or frame. Users can easily set rules in this function. This rule is mainly used in spark sessions for registering and applying for the column needed. In the Spark, there are also some inbuilt functions. This inbuilt function can be. It can be used for columns over the Spark. This kind of inbuilt function is pre-loaded in memory. The result of the Spark is returned the transformed column value. The inbuilt function returns some stored values and returns through the column in the Spark of the data set or data model. If the inbuilt function is user defined, then the loaded first in the memory of the Spark. The column values are passed through the iterates over every column in the Spark of the data frame and apply the logic to it. Method 1:Now we give the program code of the apply a function to a single column of a csv in Spark in Python. To use the CSV file in Spark, we use a method which is spark.read.csv. The program is given in below: Code: Output: Now we compile the above program and run it in any manner. After running the program, we found the output, and this output is given below - 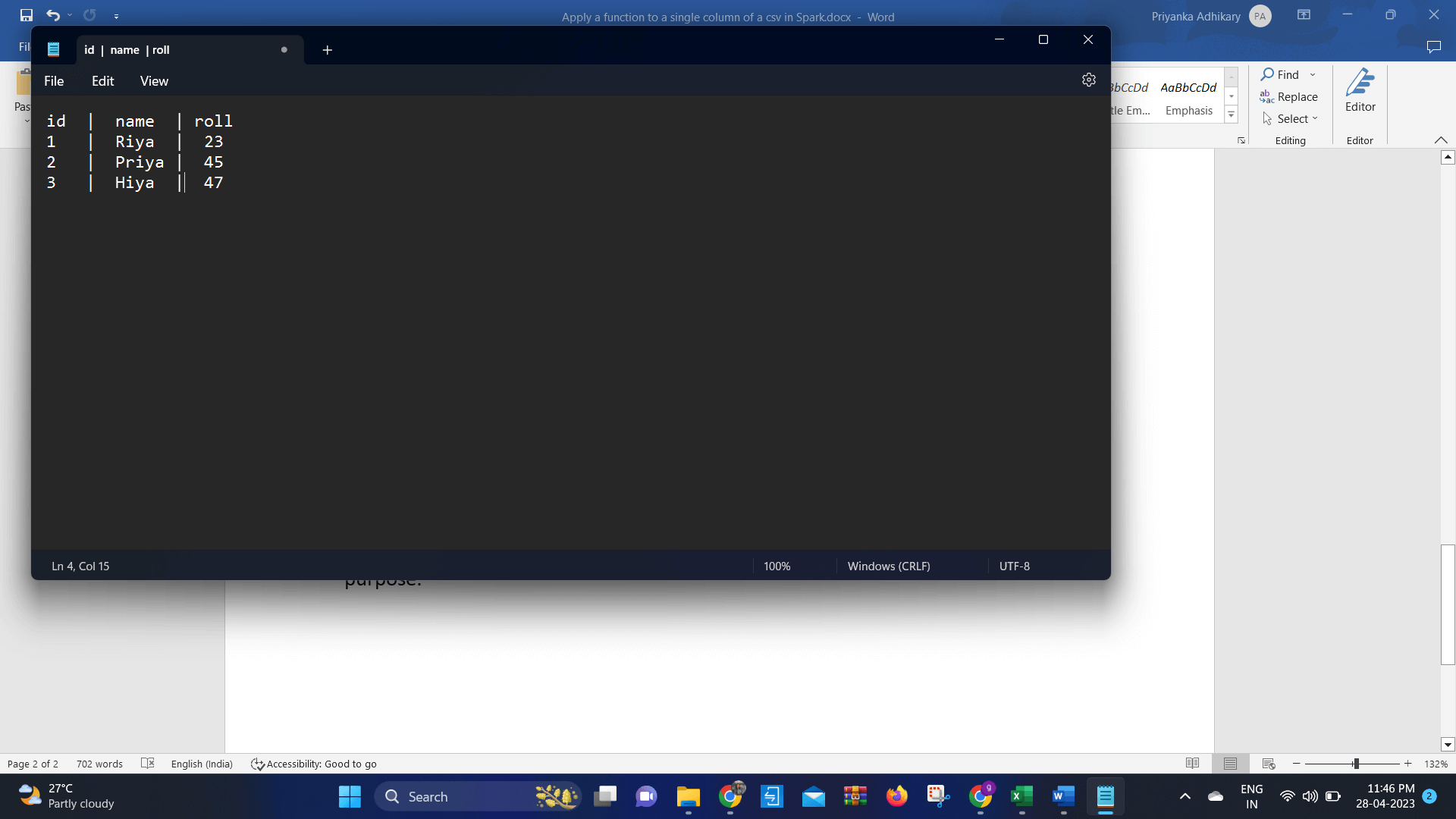 Explanation: By that, we can load the csv file quickly in Spark. Also, here we can apply this function in a single column. In this example, we can apply an inbuilt function to increment the age by a column. To apply this kind of function, we can use a method named is withColumn. Method 2Now we give the program code of the apply a function to a single column of a csv in Spark in Python. To use the CSV file in Spark, we use a method withColumn. The program is given in below: Code: Output:  Explanation: In this example, we use the col method for selecting the roll and incrementing it by 1. We can also use the valid spark expression and use the withColumn method. ConclusionIn this tutorial, we have discussed how to apply a function to a single column of a csv in Spark. Here we use two methods withColumn and spark.read.csv. We also share the working principle of csv in Spark and also share some examples of it for the learning purpose. Next TopiccalibrateHandEye() Python OpenCV |











We provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India




